All published articles of this journal are available on ScienceDirect.

Synthesis Methods for Meta-Analysis: A Scoping Review
Authors Info & Affiliations
Abstract
Background
Meta-analysis is a statistical technique to combine and summarize prior quantitative studies to assess the impact of a specific subject or intervention. Synthesis analysis, which is derived from meta-analysis, extends meta-analysis by estimating the multivariable relationship between predictors and outcomes.
Objective
This study aims to conduct a comprehensive scoping review to identify and map the extent of available research on methodological and applied synthesis analysis across different statistical responses.
Methods
Eligible studies, such as peer-reviewed articles published in English between 2000 and 2025 that presented methodological innovations and applied examples relevant to a range of statistical outcomes, were included. Systematic searches were conducted in major databases, e.g., PubMed, Google Scholar, and Scopus. Studies lacking sufficient methodological detail or focusing primarily on non-statistical model analysis were excluded.
Discussion
Synthesis analysis has advanced from simple univariable methods to advanced multivariable frameworks capable of handling incomplete, heterogeneous, and summary-only data. While these approaches improved estimation accuracy and enhanced clinical risk models, their application remains limited to mostly continuous and binary outcomes. A major gap is the absence of synthesis methods for time-to-event data, which is critical for survival analysis and clinical decision-making.
Conclusion
Synthesis analysis is a promising tool for integrating incomplete data, but current methods lack support for survival and complex outcomes. Future research should prioritize these extensions for broader clinical and public health impact.
1. INTRODUCTION
Meta-analysis or “analysis of analyses” [1, 2] refers to results obtained by combining and analyzing data from different studies conducted on similar research topics [3]. In statistical terms, meta-analysis is defined as a technique for amalgamating, summarizing, and reviewing previous quantitative research [4]. The primary objective of meta-analysis is to increase statistical inference and provide more precise estimates of effect size by pooling data from multiple smaller studies [5]. Additionally, meta-analysis typically leads to narrower confidence intervals and more stable effect estimates, reflecting stronger evidence than any single study can provide [6]. However, meta-analytical methods rely on sufficient, consistent data across individual studies [7]. Missing or partial reporting, such as lack of correlations or variances, limits the ability to include such studies in quantitative synthesis [8, 9]. Without sufficient overlap in reported outcomes, combining results statistically becomes inconsistent or biased [10, 11].
To address this problem, Samsa et al. proposed a multivariate meta-analytic modeling method called “synthesis analysis,” which refers to the challenge of integrating information from studies that lack complete multivariate data [12]. They used the term synthesis for their new statistical method even though the general idea of “synthesis in research” is understood as the integration and interpretation of multiple pieces of evidence to produce a new, coherent understanding [13]. In statistics, synthesis analysis is a methodology that constructs a multivariate regression model by integrating univariate regression coefficients and pairwise correlations from multiple independent studies or data sources [4]. This method is particularly useful in settings where individual studies are incomplete, reporting only subsets of predictors or univariate associations. It enables researchers to estimate comprehensive multivariate relationships when no single dataset contains all predictors of interest together with the outcome variable [12].
Over the years, research on synthesis analysis has been scattered across methodological and applied domains. In 2005, the pioneering work on synthesis analysis described a methodological innovation which used widely reported univariate estimates and correlations for continuous outcomes [12]. The newly emerged synthesis method was extended in 2009, improving the method by eliminating the normality assumption, reducing bias, and allowing for variance estimation [4]. Soon after, synthesis analysis appeared in genetic studies [14], followed by a methodological framework for binary outcomes, building logistic regression prediction models [15, 16]. All these methods created theoretical frameworks for various statistical outcomes, including simulation-based studies and related examples. The applied approach of synthesis analysis showed the development of multivariate disease prediction models in scenarios where a comprehensive dataset containing both disease outcomes and all relevant predictors of interest is not available [18].
For example, the Framingham Coronary Heart Disease (CHD) model is widely recognized as a comprehensive tool, but it does not include several important risk factors such as body mass index (BMI), family history of CHD, and C-reactive protein [19-21] for risk prediction. To address this gap, Hu et al. provided a new CHD prediction model by incorporating additional risk factors through the novel synthesis modeling approach [17, 22]. Thus, developing and validating these methods would enable more robust and generalizable risk prediction for clinical decision-making, particularly in contexts of non-communicable diseases, i.e., stroke, coronary heart disease, and cancer.
However, most existing studies have concentrated on a narrow range of statistical methods and have been applied primarily within specific medical domains, such as stroke and coronary heart disease, limiting their generalizability to other types of statistical responses. Given the increasing role of clinical decision-making in public health practice, it is essential to deepen the understanding of how commonly used statistical outcomes are applied in real-world settings, such as time-to-event outcomes. A thorough understanding of synthesis analysis practices in public health can help identify existing challenges and support efforts to improve the reporting and interpretation of statistical outcomes. Therefore, a scoping review was conducted to systematically examine how synthesis methods are currently applied and analyzed in the literature. Specifically, this research aimed to: (1) identify existing synthesis analysis methodologies across various statistical response types, summarize their current applications, and highlight areas where further research is needed; and (2) describe how synthesis methods were applied in clinical practice to estimate risk prediction models.
2. MATERIALS AND METHODS
This review was conducted per the Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR) checklist and explanation (https://www.prisma-statement. org/scoping). The PRISMA-ScR was developed based on published recommendations by the EQUATOR (Enhancing the QUAlity and Transparency Of health Research) Network for reporting guideline development.
The electronic databases PubMed, Google Scholar, and Scopus were searched. Studies were identified in the search using the following keywords: “synthesis analysis,” “meta-analysis,” “linear model,” “logistic model,” “combining statistical models,” “multivariate model,” and “prediction model”. These keywords were selected to incorporate relevant publications through specific terms like “synthesis analysis,” “multivariate model,” “linear model,” and “logistic model,” as well as more general terms such as “prediction model” and “combined statistical model” to ensure comprehensive literature extraction.
All eligible studies identified via the “snowballing” search strategy were included in the review [23]. Studies were included if they met the following criteria: (1) the study was published as a peer-reviewed journal article; (2) the article presented methodological development and applied examples of the synthesis method for statistical outcomes; (3) the publication appeared between 2000 and 2025; (4) the manuscript was written in English.
Exclusion of studies was based on specific eligibility criteria such as: (1) the article described synthesis analysis or meta-analysis without providing sufficient methodological or applied detail for implementation; (2) the primary objective of the method was not the analysis of statistical responses. For example, articles with random-effects meta-analysis or synthesis of correlated endpoints were excluded [24, 25]; (3) publications appeared before 2000; (4) the article was not written in English.
The selected articles were reviewed, and relevant data were manually extracted using Microsoft Word and organized into a tabular format. The extracted data included authors, article title, year of publication, study aims, methods, outcome measures, findings, and significance of the results (Tables S1 and S2). The table facilitated the identification of methodologies, techniques/ applications, advantages, and disadvantages within the included studies. The collected details were then summarized and presented in a narrative format.
3. RESULTS
The initial database search in Google Scholar, PubMed, and Scopus identified 248 studies as potentially relevant. After removing duplicates, the screening process included titles, abstracts, and method sections to further narrow the search. Of these, only 10 studies published between 2004 and 2017 addressed methodological and implementation research across various contexts of synthesis analysis and were included in this review. A flow diagram of the study showing the identification of studies via databases is shown in Fig. (1). The PRISMA checklist is attached as an additional file (Supplementary Material).
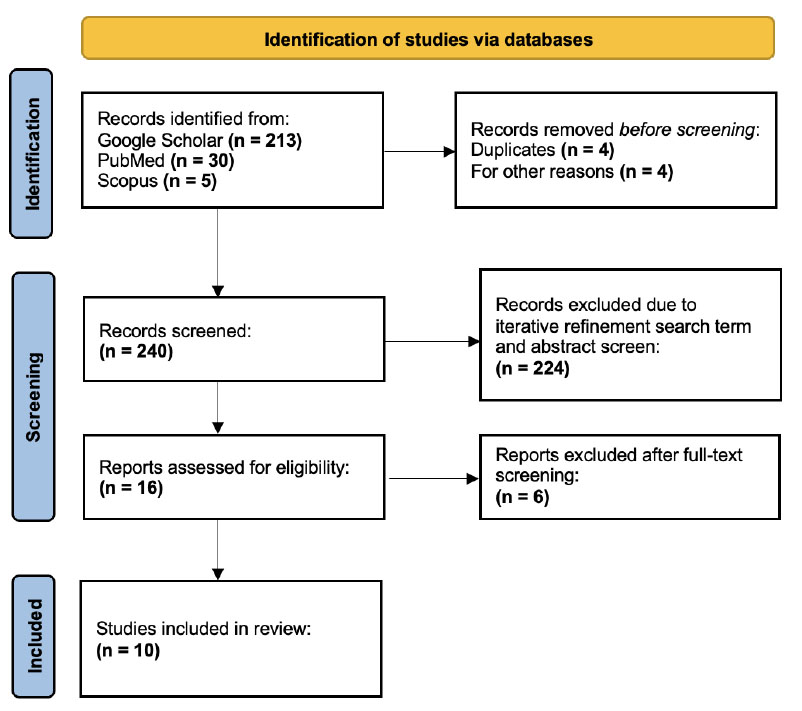
Flow diagram of the study.
3.1. Methodological Synthesis Analysis
The reviewed studies collectively propose and assess new methods for synthesizing data from various sources to develop multivariable models for prediction and risk assessment. Thus, the methodological studies identified in this review track the evolution of synthesis analysis, which combines incomplete or partial information across studies into coherent multivariable models.
Early work by Samsa, Hu, and Root [12] introduced a univariable synthesis method that integrated regression coefficients, standard deviations, and correlations from multiple datasets through simulation. This approach was robust in predicting outcomes but demonstrated limitations in accurately estimating regression coefficients. Zhou et al. [4] extended synthesis analysis for continuous outcomes by developing a method that eliminated normality assumptions, reduced bias, and provided variance estimation. Their approach was based on solving systems of linear equations derived from conditional expectations, combining them into a single, unified marginal model that describes how all variables relate to the outcome. Hence, they showed superior mean bias and mean squared error (MSE) performance in simulation studies compared to the Samsa-Hu-Root (SHR) method, particularly under skewed distributions.
Further methodological advancement was made by Bagos and Liakopoulos [14], who incorporated linkage disequilibrium (LD) information into a multivariate meta-analysis of genetic association studies. This allowed for the computation of within-study covariances and increased the precision and power of identifying causal variants across studies. Later, Bagos [15] provided a general theoretical framework for estimating the covariance of correlated log-odds ratios from summary data, improving meta-analytical practice without requiring access to raw datasets.
Finally, Sheng et al. [16] addressed the methodological gap in synthesizing logistic regression models with binary outcomes. This method provided theoretically proven coefficient estimation, including advantages over earlier approaches. However, the method demonstrated sensitivity to distributional assumptions. Simulation studies suggested that while Hu and Root’s earlier method often outperformed in prediction under non-normal data, the new logistic-specific synthesis improved estimation with larger, normally distributed samples [16].
Collectively, these methodological contributions demonstrate a progression from univariate synthesis toward increasingly complex and flexible approaches, covering continuous and binary outcomes, genetic association studies, and theoretical covariance estimation. Across studies, synthesis analysis was consistently shown to approximate multivariate models built on incomplete data, with performance varying depending on distributional assumptions and data context.
3.2. Applied Synthesis Analysis
Applications of synthesis analysis methods across diverse domains have demonstrated their practical utility in improving predictive modeling and meta-analytic synthesis. In 2005, Hu and Root [17] introduced the synthesis analysis framework for coronary heart disease (CHD) prediction using multiple longitudinal datasets. Their approach incorporated univariate regression coefficients and cross-sectional correlation matrices while facilitating model development across heterogeneous sources. This method had greater flexibility and capacity for external validation, with discriminatory performance (AUC loss of only ~0.001). Tang, Caudy, and Taxman [18] extended this applied focus by proposing a synthesis method for aggregating results from multiple meta-analyses. This two-step frequentist procedure is particularly useful for conflicting or updated evidence bases. This application allowed conversion of diverse effect sizes to a common metric and demonstrated effectiveness in synthesizing both homogeneous and heterogeneous meta-analytic data.
Hu, Root, and Duncan [22] demonstrated the application of the synthesis method using NHANES III and Atherosclerosis Risk in Communities (ARIC) cohort data. They integrated six additional risk factors, including family history of CHD (father/brother with CHD before age 60 years or mother/sister before age 65 years), physical exercise level (lower, equal, or higher compared with peers), body mass index (kg/m2), serum albumin, apolipoprotein A, and plasma fibrinogen into the Framingham Risk Score (FRS) using synthesis analysis to construct the NEW-CHD model. This model showed improved discrimination, calibration, and reclassification with enhanced risk prediction. Similarly, Zhou et al. [26] expanded the Framingham Stroke Risk Score (FSRS) by incorporating seven literature-based predictors, e.g., African American ethnicity, physical exercise level (low, moderate, or high based on frequency and intensity of activity), body mass index (kg/m2), waist circumference, height, high-density lipoprotein (HDL) cholesterol, and use of hormone replacement therapy in postmenopausal females only. The resulting NEW-STROKE model demonstrated statistically significant improvements in all predictive metrics while emphasizing the method’s strength in augmenting established clinical tools.
Finally, Jackson et al. [27] reviewed the broader use of multivariate meta-analysis and emphasized its promise in handling correlated outcomes and improving precision. Their findings underscored the statistical advantages of borrowing strength across correlated measures but also highlighted limitations such as increased assumption burdens and the need for complete data matrices.
4. DISCUSSION
The purpose of this review is to present an overview of the published literature on synthesis analysis methods, summarize their applications, and identify areas requiring further research. Through a comprehensive examination of the literature, this review highlights how synthesis analysis has evolved as both a statistical concept and an applied tool across diverse research domains. The findings indicate a scarcity of studies focused specifically on statistical methodology and a limited amount of research regarding its implementation in this area.
It is important to note that the term “synthesis” was not used consistently across the studies included. While some explicitly described their approach as synthesis analysis, others described related methods (e.g., multivariate meta-analysis) that shared the same goal of integrating incomplete or heterogeneous information across studies. These were included to provide a comprehensive overview of developments relevant to synthesis analysis. Based on the primary contribution of each article, the findings were distinguished into two parts: methodological and applied synthesis analysis. Section 3.1 focuses on methodological developments, i.e., studies whose primary contribution is the theoretical or statistical formulation of synthesis analysis (e.g., estimation frameworks, assumptions, simulation performance). In contrast, Section 3.2 focuses on applied implementations, where synthesis analysis is used as a tool to enhance real-world prediction models (e.g., CHD and stroke risk scores).
The methods of synthesis analysis have evolved from univariable approaches to more advanced multivariable frameworks that incorporate incomplete or heterogeneous data from various studies. Advancements in methodology have enhanced estimation under non-normal distributions for continuous outcomes, enabled the modeling of correlated predictors, and improved prediction accuracy using only summary-level inputs. For binary outcomes, the methodological framework provided improved performance with increased sample size, especially for normally distributed data. These methodological frameworks provided real data examples, such as National Health and Nutrition Examination Survey (NHANES) data, which enable researchers to derive more accurate estimates of multivariate model coefficients, in contrast to the less rigorous approach of using univariate model coefficients to represent multivariate relationships.
Applied studies have effectively enhanced clinical risk models, including the Framingham Risk Score and Stroke Risk Score, showing improvements in discrimination, calibration, and practical significance. Synthesis analysis has contributed to significant and wide-ranging benefits for public health. The method enables the construction of multivariable risk prediction models without the need for large-scale primary data collection, which is particularly valuable in resource-limited settings where conducting comprehensive longitudinal studies is financially unfeasible [12]. The use of multiple risk factors within a single model also strengthens risk stratification across populations. This improvement helps earlier recognition of individuals at high risk and supports more efficient delivery of preventive interventions such as lifestyle modification programs and pharmacological treatments [22]. Furthermore, the method allows accumulated epidemiological evidence to be converted directly into practical clinical risk tools. This accelerates the translation of evidence into practice and removes the need to repeat expensive primary studies [26]. However, a consistent limitation across all studies is that synthesis analysis remains confined to continuous and binary outcomes.
To date, no research has proposed or assessed a synthesis framework for time-to-event or survival data, which are essential in medical research and clinical decision-making [28]. Survival analysis (also called time-to-event analysis or failure-time analysis) is a set of statistical procedures that focus on time-to-event data, with the outcome variable being the time until an event (e.g., death, disease relapse, or recovery) occurs [29]. Extending synthesis analysis to time-to-event outcomes would be a valuable and novel meta-analytic approach that could synthesize information from various public health studies. Without a synthesis analysis approach for time-to-event outcomes, valuable information from multiple incomplete studies remains underutilized, limiting our ability to provide robust, evidence-based survival predictions and inform patient care [30].
Future research should prioritize the development of synthesis methods for time-to-event and other statistical outcomes, including ordinal and repeated-measures outcomes. This statistical framework can be applied to address infectious diseases and undiagnosed health conditions, including obesity, elevated serum cholesterol levels, hypertension, dietary and nutritional status, as well as cardiovascular and cognitive health [31, 32].
Therefore, expanding the statistical scope of synthesis analysis, alongside improving usability and transparency, will be critical for broader implementation.
CONCLUSION
This scoping review highlights synthesis analysis as a promising approach for building multivariate models from incomplete data sources. While effective for continuous and binary outcomes, current methods lack support for time-to-event and other complex responses. Addressing this gap is crucial for broader application in public health and clinical decision-making.
AUTHORS’ CONTRIBUTIONS
The authors confirm contribution to the paper as follows: N.H., R.I.N.: Study conception and design; R.I.N.: Data collection; R.I.N., N.H., M.M.H.: Analysis and interpretation of results; R.I.N.: Draft manuscript. All authors reviewed the results and approved the final version of the manuscript.
LIST OF ABBREVIATIONS
| BMI | = Body mass index |
| MSE | = Mean squared error |
| SHR | = Samsa-Hu-Root method |
| LD | = Linkage disequilibrium |
| CHD | = Coronary heart disease |
| FRS | = Framingham Risk Score |
| NHANES | = National Health and Nutrition Examination Survey data |
| ARIC | = Atherosclerosis Risk in Communities |
AVAILABILITY OF DATA AND MATERIALS
The data and supporting information are available in the article.
CONFLICT OF INTEREST
Dr. Nan Hu is the Editorial Advisory Board Member of The Open Public Health Journal.
ACKNOWLEDGEMENTS
Declared none.

